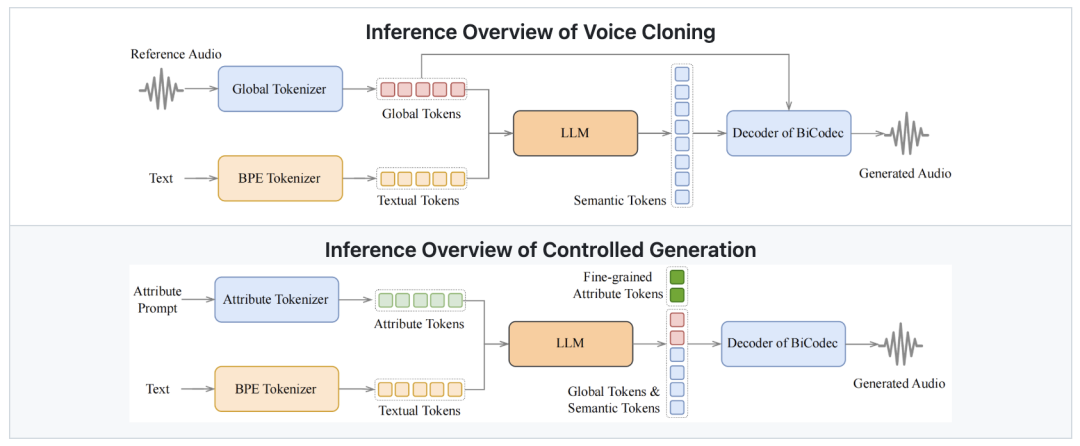
在 TTS(文本转语音)技术的快速发展下,如何生成更加自然、可控、个性化的 AI 语音,成为了语音合成领域的核心挑战。 传统的 TTS 系统虽然能生成高质量语音,但往往存在 控制能力有限、跨语言表现较差、声音风格固定 等问题。 Spark-TTS 作为一款刚刚开源的高质量语音合成(TTS)系统。 不仅支持零样本语音克隆,还能进行细粒度语音控制,包括语速、音调、语气等多项参数调节,同时具备跨语言生成能力,让 AI 语音变得更加灵活、多样化。 Spark-TTS 兼具高音质、可控性、跨语言能力,并且 完全开源,是当前最灵活的开源 TTS 方案之一。 克隆项目 创建Python虚拟环境,安装Python依赖 模型下载(两种方式): 运行演示: 或者直接在命令行中进行推理: 如果使用Web界面,可以使用以下命令启用: 可以直接通过界面执行语音克隆和语音创建。支持上传参考音频或直接录制音频。 后裔: 周杰伦: 徐志胜: 哪吒: 殷夫人: 由于其自然的声音效果和强大的控制能力,Spark-TTS 非常适合以下用途: Spark-TTS 是一款创新的 TTS 模型,凭借 BiCodec 编解码器和 Qwen-2.5 思维链技术,实现了高质量、可控的语音生成。 它支持零样本语音克隆、细粒度语音调整和跨语言合成,效果自然且高效,非常适合有声读物、AI配音等应用场景。 GitHub 项目地址:https://github.com/SparkAudio/Spark-TTS
核心能力
安装部署
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTSconda create -n sparktts -y python=3.12
conda activate sparktts
pip install -r requirements.txt
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
mkdir -p pretrained_models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5Bcd example
bash infer.shpython -m cli.inference
--text "text to synthesis."
--device 0
--save_dir "path/to/save/audio"
--model_dir pretrained_models/Spark-TTS-0.5B
--prompt_text "transcript of the prompt audio"
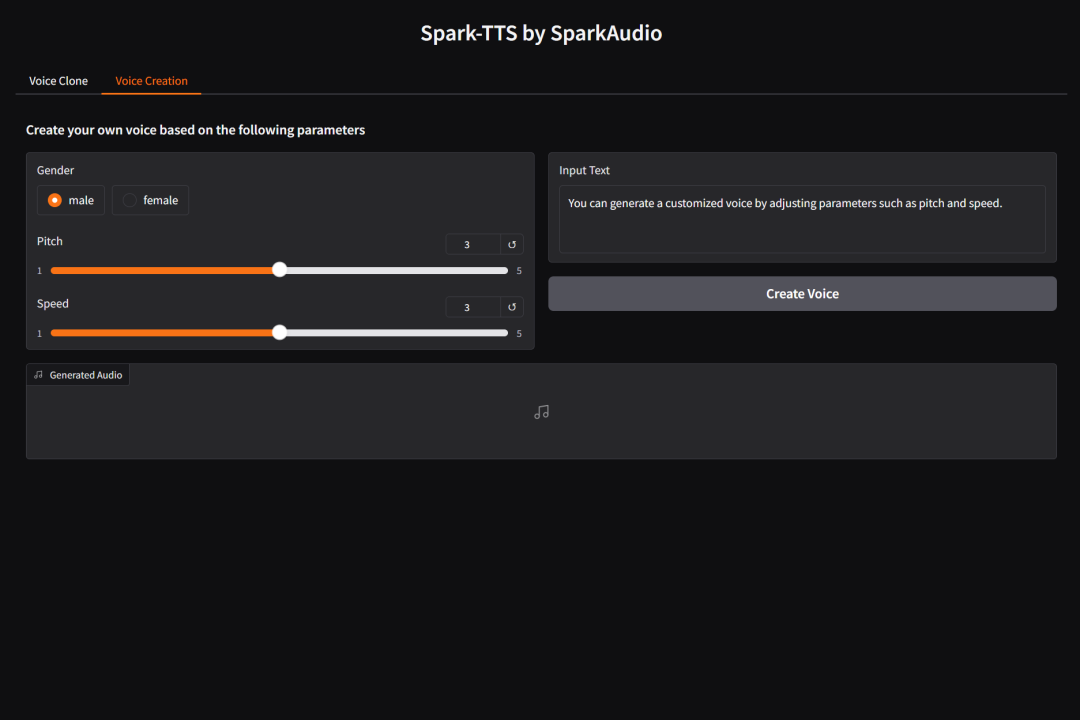
--prompt_speech_path "path/to/prompt_audio"python webui.py --device 0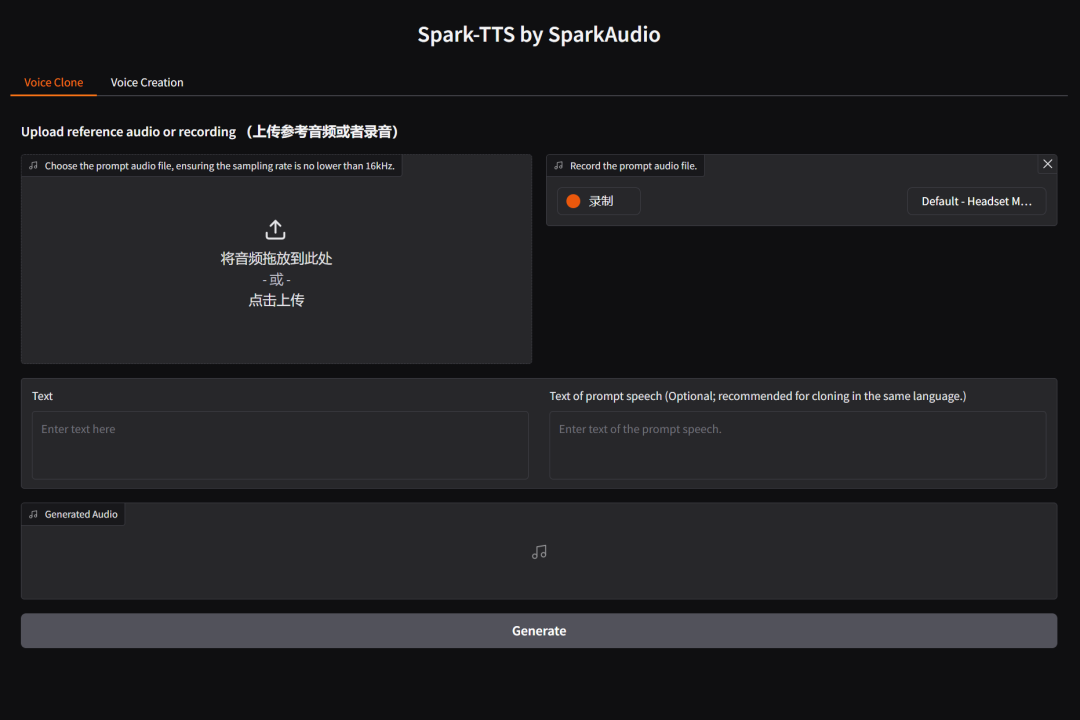
语音演示
应用场景
写在最后

太给力了!刚刚开源的TTS模型,1:1零样本声音克隆,连呼吸节奏都能控制!
未经允许不得转载:桃花坞里桃花庵 » 太给力了!刚刚开源的TTS模型,1:1零样本声音克隆,连呼吸节奏都能控制!









评论前必须登录!
注册